

起步
WARNING
由于 face-api.js 已经有一段时间没有活跃更新了,而谷歌推出的 mediapipe 除了可以跨平台地检测人脸,甚至还可以检测身体动作等。 这无疑是我们更想要的东西,所以此后将会从 face-api.js 迁移为使用 mediapipe/Holistic。
此部分内容将会被废弃。
使用已有的 face-api.js 配合浏览器的 WebCam 可以很方便地搭建出一个人近乎实时的人脸检测效果 Demo。
face_landmark_68_mode 仅 350KB。
而我们将这些点坐标与其代表含义建立对应关系即可。

我们可以看到 dlib 给出的 68 个点对应的位置。
为了更方便的使用,我们可以将其各点用对象进行命名并一一对应。
见 packages/vtuber/face.ts。
/**
* 脸部 68 个特征点
*/
export const FaceMap = {
brow: {
left: [17, 18, 19, 20, 21],
right: [22, 23, 24, 25, 26],
},
eyes: {
left: [36, 37, 38, 39, 40, 41],
right: [42, 43, 44, 45, 46, 47],
},
center: [30],
nose: {
bridge: [27, 28, 29, 30],
// 鼻孔
nostrils: [31, 32, 33, 34, 35],
},
mouth: {
/**
* 上嘴唇
*/
upperLip: {
left: 48,
right: 54,
top: [49, 50, 51, 52, 53],
bottom: [61, 62, 63],
},
/**
* 下嘴唇
*/
lowerLip: {
left: 60,
right: 64,
top: [65, 66, 67],
bottom: [55, 56, 57, 58, 59, 60],
},
},
// 下巴
jaw: [6, 7, 8, 9, 10],
// 边
border: [0, 1, 2, 3, 4, 5, 11, 12, 13, 14, 15, 16],
}没错,是我自己一个个分的。
三二一,茄子
总之,咱们得先有一个 Vtuber 形象用于映射。
使用 canvas 来绘制图形 - MDN 中的笑脸是个不错的例子。
本质便是由弧线、圆圈组成,我们就绘制它来作为我们的初始形象吧。
Python 里有 NumPy,JavaScript 里就用 mathjs 凑合一下吧。
说了这么多,发现还是先用现有的模型更方便,Kizuna AI 绊爱 官网 可以下载到爱酱的模型(非商业使用)。
参照 Three.js 的 mmd 载入方式加载爱酱的模型。
统计特征点
已知 30 是鼻子的中心点,而我们需要使用眉毛的中心与下巴的中心构成三角形,以计算头部的左右旋转角度。
头的左右旋转
那么首先我们需要获取标准的正面,我们假设人的正脸是对称的,也就是说 眉毛的中心,鼻子的中心,下巴的中心 应当是可以连成直线的。
眉毛的中心,我们可以通过取左眉毛中点与右眉毛中点连线的中点。
const browCenter = points[FaceMap.brow.left[2]]
.add(points[FaceMap.brow.right[2]])
.div({ x: 2, y: 2 })鼻子中心
const noseCenter = points[FaceMap.nose.nostrils[2]]下巴中心
const jawCenter = points[FaceMap.jaw[2]]当转头时,三个点相连,应当是一个三角形。
我们暂且将眉毛中心到下巴中心这条最长的线称之为 中线,眉毛中心到鼻子中心的这条线称之为 上斜线。
const midLine = browCenter.sub(jawCenter)
// 上斜边
const topLine = browCenter.sub(noseCenter)
// 转化为 Three.js 里的向量以使用叉乘
const midLineVector = new THREE.Vector2(midLine.x, midLine.y)
const topLineVector = new THREE.Vector2(topLine.x, topLine.y)中线与上斜线进行 叉乘(向量积),则可以得到以这两个向量为边的平行四边形面积。
鼻子转过的高度 = 平行四边形面积 / 中线长度
而所谓 鼻子转过的高度 即与「脸水平旋转的角度」正相关。
// 旋转头部模型的 Y 轴
const rotationY
= midlineVector.cross(topLineVector) / (midLineLength * midLineLength)
// ...
const ratio = 5
head.rotation.y = rotationY * ratio也许应当有一个正确的换算方式,但是我测试放大倍率为
5的时候效果还不错,总之先将就用下吧!

看看效果吧。(有点卡!真的只是有点吗?)
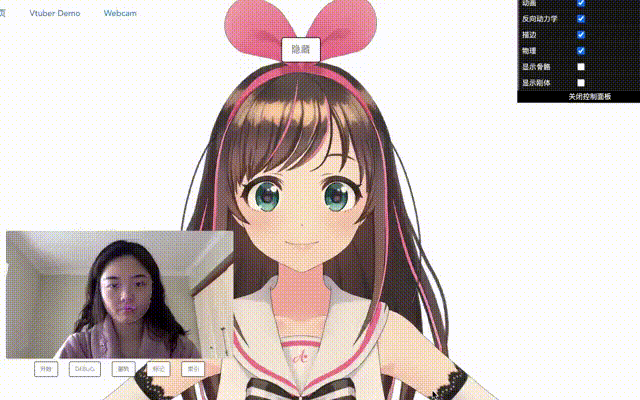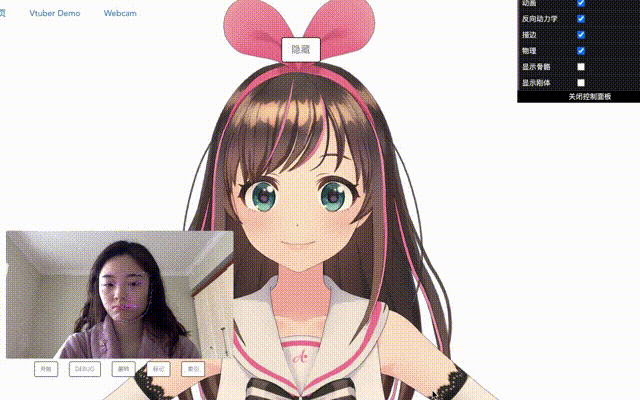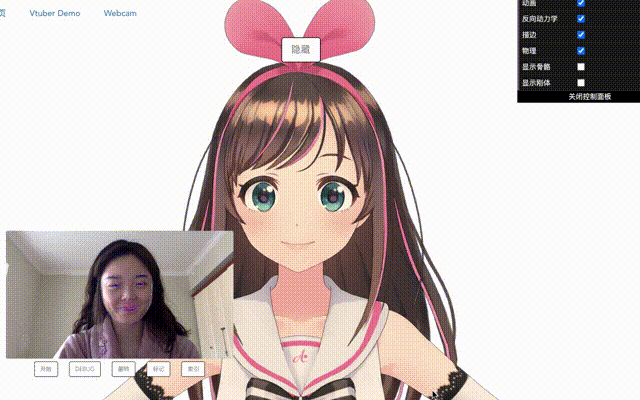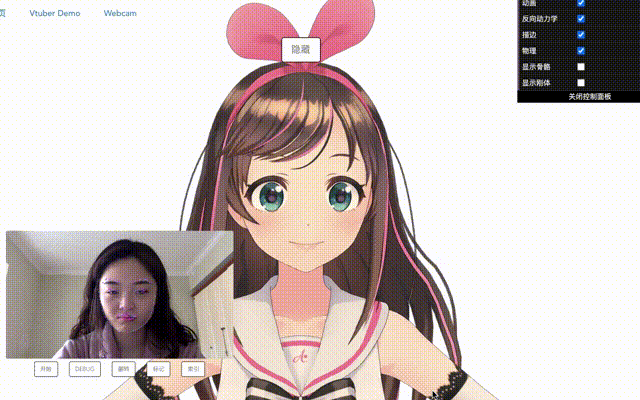
上下旋转
我们默认人是正对镜头的,且人脸是左右对称的,所以左右旋转很好实现。
但是上下旋转却不一样,我们并不知道用户什么情况下是正对镜头的。 也就是说我们应该有一张标准脸(即用户正对镜头时),并将此时 眉毛的中心,鼻子的中心,下巴的中心 三个点构成的直线长度比例作为用户正对镜头时的比例。
并由比值的增减来判断用户在抬头还是低头。
因此「脸垂直旋转的角度」应当与「 上斜线 在 中线 上的投影长度」与 「中线」的比值有关。 也就是说,用户抬头时,比值会减小,用户低头时,比值则会增大。
还记得点乘公式吗?点积(数量积)
上斜线与中线的向量积,即为 上斜线在中线上的投影长度(上斜线向量 * ) * 中线长度
上斜线向量 * = 上斜线在中线上的投影长度
因此我们想要得到比值,拿其除以两次中线长度即可。
// 垂直旋转量
const rotation
= midLineVector.dot(topLineVector) / (midLineLength * midLineLength) - 0.5对了,正常的上斜线比上中线是有一个比值的。 每个人可能有所区别,但为了方便起见,我们假设普通人的眉毛中心到鼻子的长度约等于眉毛到下巴的一半,所以我们还要在比例值上减去原有的 0.5,得到头真正应该旋转的角度。
可以看到在此过程中,我们可能需要重复计算 midLineVector 与 topLineVector 以及 midLineLength * midLineLength。
因此我们可以将水平与垂直旋转量公共部分合并到一起计算,进行些许优化。